
♥️7분 빠른 소식 전달해 드립니다♥️
[인프라] 클라우드 컴포넌트 리소스(가상서버/네트워크/스토리지) 본문
가상 서버가 생성되기까지의 처리 흐름
아래는 API를 통해 가상 서버의 생성 요청을 접수한 후, 오픈스택 내부에서 벌어지는 처리 내용들을 도식화한 것이다. 실제로는 이보다 더 복잡게 처리되지만 큰 흐름을 파악할 수 있도록 주요 동작만 표현하고 세부적인 내용은 생략되었다.

1. 가상 서버 생성 요청을 메시지 큐에 넣기
가상 서버를 생성하는 API가 실행되면 일단 큐에 메시지를 넣어 비동기로 처리한다. 오픈스택 내부에서는 모든 처리가 이 메시지 큐를 통해 이루어진다. 많은 서버들이 메시지를 효율적으로 주고 받도록 중계하는 오픈스택의 핵심 미들웨어로 AMQP라는 표준 프로토콜을 사용한다. 가상 서버 생성 요청이 큐에 들어가는 시점에 생성할 가성 서버의 구성 정보와 상태 정보가 구성관리 데이터베이스에 저장된다. 'GET https://{compute}/v2/{tenant_id}/servers/{server_id}'를 통해 확인 가능하다. 이 시점에서 가상 서버의 상태 정보는 'Status: BUILDING'으로 아직 서버를 생성중이라는 의미다.
2. 스케줄러에 요청 전달하기
메시지 큐에 들어간 생성 요청 메시지는 스케줄러(Conductor)라고 부르는 프로세스가 꺼낸다. 이후 가상 서버를 생성하기 위한 처리를 시작한다. 이렇게 시케줄러 프로세스를 다중화하여 처리하면 가용성이 높아지는 효과가 있다. 여러 개의 스케줄러가 동시에 동작하는 상황에서도 하나의 요청은 반드시 한개의 스케줄러가 처리한다. 요청이 폭주할때는 여러개의 시케줄러로 분산처리된다. 오픈스택은 대규모 환경에서 운영되는 것을 감안하여 설계되어 있기 때문에 이러한 가용성과 성능 향상을 고려한 메커니즘이 잘 갖추어져 있다.
3. 가상 서버를 기동할 호스트 결정하기
오픈스택은 여러개의 호스트(하이퍼바이저)를 큰 덩어리로 묶고 그위에 가상 서버 같은 리소스를 배치한다. 이때 어느 호스트에 가상 서버를 배치할 것인가 결정하는 규칙이 중요하다. 과거에는 가상 서버를 배치할 호스트를 관리자가 직접 결정했지만 오픈스택은 이부분이 자동으로 처리된다.
오픈스택은 내부의 '상태 관리 데이터베이스'에 각 호스트들의 리소스 사용상태를 기록하고 이 정보를 주기적으로 갱신한다. 스케줄러는 메시지 큐에서 가상 서버를 생성해달라는 메시지를 꺼낸후, 상태 관리 데이터베이스의 정보를 보고 가상 서버에 필요한 리소스를 가진 호스트를 찾는다. 가상 서버를 기동할만한 호스트가 없다면 오류가 발생하게되고 구성 관리 데이터베이스의 가상 서버 상태는 'ERROR'로 기록된다.
스케줄러가 호스트를 선택할 때는 기본 항목으로 CPU 코어 개수와 메모리 용량등을 고려한다. 이부분에 대해 자세히 알고 싶다면 오픈스택 공식 문서 중 'Configuration Guides'의 스케줄러 부분을 참고하면 된다.
4. 호스트에 가상 서버 기동을 지시하기
스케줄러가 가상 서버를 기동할 호스트를 결정했다면 이제 그 호스트에 가상 서버를 기동하도록 지시한다. 기동 지시 메시지는 메시지 큐에 들어가는데 참고로 메시지가 전달되는 방법으로는 임의의 1대가 메시지를 받는 방식과 특정한 1대가 메시지를 받는 방식이 있다.
5. 메시지 수신과 가상 서버의 생성하기
메시지 큐를 통해 가상 서버 기동 지시를 받은 호스트는 드디어 가상 서버를 만들기 시작한다. 이때는 가상 서버를 생성하는 것 이외에도 기동할 템플릿 이미지를 가져오고 가상 서버에 할당할 IP 주소를 확보하는 작업, 지정한 네트워크로 접속하기 위한 준비 등의 다양한 작업들이 처리된다. 템플릿 이미지를 찾을 수 없거나 가상 네트워크 설정에 실패하는 등, 가상 서버 생성을 하지 못한 경우에는 구성 관리 데이터베이스 상태 정보가 'ERROR'로 기록된다.
6. 가상 서버의 상태 갱신하기
가상 서버를 생성하고 기동까지 성공했다면 구성 관리 데이터베이스의 상태를 'ACTIVE'로 갱신한다. 사용자는 API를 통해 가상 서버의 생성 상태를 확인할 수 있어서 작업에 대한 최종적인 성공여부를 판단할 수 있다.
오픈스택에는 이외에도 많은 API들이 있는데 이 API들을 사용할때 공통된 패턴이 있다. 예를들어 GET 방식을 사용하는 API는 사용자로부터 요청 받은 정보를 구성 관리 데이터베이스에서 찾은 다음 응답으로 알려준다. POST/PUT/DELETE 방식을 사용하는 API는 요청이 들어오면 처리를 끝낸 후, 응답하는 것이 아니라 일단 메시지 큐에 요청을 넣고 처리 완료 여부와 상관없이 사용자에게 응답한다.
이때, 실제로는 비동기 방식으로 처리되고 그 결과는 최종적으로 구성 관리 데이터베이스에 반영된다. 사용자는 이후 결과를 확인하기 위한 GET 방식으로 API를 호출하여 상태를 확인한다. 클라우드 API들은 대체로 GT 방식이면 바로 결과를 응답한다. POST/PUT/DELETE 방식을 사용하는 API인 경우 비동기로 처리하며, 이후 결과 확인을 위해 정기적으로 GET 방식 호출을 통해 결과를 확인하는 공통 패턴을 가지고 있다.
서버리소스는 가상화 기술을 사용해본 사람에게는 비교적 이해가 쉬운 내용이다.
블록 스토리지 리소스 제어
블록스토리지 리소스는 크게 볼륨과 스냅샷 두 종류로 구분된다. 볼륨은 실제로 서버에 연결되는 디스크를 의미하고 휘발되지 않고 영속적으로 보관되는 특징이 있다. 디스크가 물리적으로 삭제/고장되지 않으면 데이터가 지워지지 않는다.
스냅샷은 볼륨을 복제한 것으로 스냅샷 자체로는 서버에 직접 연결해서 쓰지 못한다. 서버에 사용하려면 일단 스냅샷을 다시 볼륨으로 복원한후, 서버에 연결해야 한다. 스냅샷은 주로 백업이나 데이터를 이행할때 사용된다.
블록 스토리지와 API
이미 기동중인 서버가 있는데 디스크 용량이 부족하여 외부 디스크를 추가해야 하는 상황을 가정한다. 과거의 물리적 인프라 환경에서는 스토리지를 증설하거나 설정하기가 상당히 까다로웠다. 스토리 장치에 디스크 영역(볼륨)을 만들기 위해서는 그 스토리지의 전용 명령이나 소프트웨어를 사용해야만 했고, 가상 머신과 연결할때도 LUN(Logical Unit Number)과 WWN(World Wide Name)을 매핑하는 등의 스토리 고유의 설정 작업이 필요했다. 클라우드에서는 이러한 작업을 어떻게 할까?
오픈 스택에서 블록 스토리지를 어할때는 볼륨을 다루기 위한 'cinder' 명령과 가상 서버를 다루기 위한 'nova' 명령을 사용한다. 이들 명령을 사용하면 내부에서 오픈스택의 각종 API들이 실행된다. 실제로 cinder 명령으로 10GB 크기의 볼륨을 만든후, nova 명령으로 가상 서버에 생성된 볼륨을 연결할 수 있다. 과거의 물리적인 인프라 환경이었다면 고려할 사항이 많았겠지만 클라우드에서는 단 두개의 명령으로 간단히 처리할 수 있다.
볼륨과 가상 서버의 연결
볼륨이 만들어졌다면 이제 볼륨을 가상 서버와 연결해야 한다. 이런 작업을 다른 말로 'attach한다'고 한다. 오픈스택에서는 'https://{compute}/v2/{tenant_id}/servers/{server_id}/os-volume_attachements'를 POST 방식으로 호출한다. 이때 '{compute}' 부분에는 Nova의 접속정보를 '{tenant_id}'에는 테넌트 ID를, '{server_id}'에는 가상서버 ID를 넣고 연결할 볼륨의 UUID 정보는 request body를 통해 함께 전달한다.
이 조작은 POST 방식으로 요청되어 비동기로 처리된다. API 호출 직후에 응답이 왔다고 하더라도 그 시점에서는 아직 연결이 완전히 끝난 상태가 아닐 수 있다. 그래서 다음 처리를 계속하기 전에 'http://{storage}/v2/{tenant_id}/volumes/{volume_id}'를 GET 방식으로 호출하여 연결처리가 완료되었는지 상태를 확인해볼 필요가 있다.
볼륨 타입
블록 스토리지의 백엔드는 물리적 디스크이다. 그래서 디스크의 특성과 설정에 따라 I/O 특성도 달라진다. 클라우드 환경에서는 볼륨 타입이라는 카테고리로 명시적으로 선택할 수 있다.
오픈 스택의 Cinder에서는 이러한 물리적인 매핑 정보를 'cinder.conf'라는 설정 파일에서 관리한다. 예를 들어 백엔드 스토리지가 리눅스 LVM(Logical Volume Management)와 GlusterFS로 구성되어 있으면 각각을 활성화하기 위해 'enabled_backends=lvm,gluster'라고 선언하고 드라이버를 설정한다.
볼륨 사이즈
볼륨 사이즈는 볼륨을 생성할때 결정한다. 단, 블록 디바이스의 특성상 가상 서버의 OS에서 파일 시스템으로 인식되는 용량까지만 사용가능하다. 볼륨은 디바이스 단위로 연결되기 때문에 OS에서 여러 디바이스를 사용한 소프트웨어 RAID를 구상할 수도 있다. 리눅스에서는 여러개의 볼륨을 서버에 연결한 상태에서 mdadm 명령으로 소프트웨어 RAID를 구성한다.
스루풋, IOPS, SR-IOV
클라우드 환경에서는 가상 서버 리소스가 블록 스토리지로 접근하기 위해 네트워크를 통과해야 한다. 그래서 백엔드 스토리지 자체의 성능도 중요하지만 가상 서버에서 블록 스토리지까지 연결되는 네트워크의 성능 역시 중요하다. 이때 성능이 어느 정도인지 가늠하기 위한 지표로는 스루풋(초당 전송 대역), IOPS(초당 input과 output의 횟수)를 사용한다.
Amazon EC2에서는 instance type에 따라 최대 스루풋이 결정된다. 만약 Amazon EC2의 스루풋 제한 때문에 병목이 발생한다면 instance type을 좀더 상위의 것으로 바꿔줄 필요가 있다.
블록 스토리지는 네트워크를 경유해서 접근하기 때문에 시스템의 구성 방식이 원인이 되어 병목이 발생할 수도 있다.
병목이 발생하거나 성능을 개선해야 한다면 대부분 앞서 설명한 것과 같은 방법으로 IOPS나 스루풋을 튜닝하면 되지만 서버측에서는 SR-IOV(Single Root I/O Virtualization)을 활용해야 할 때도 있다. SR-IOV는 가상화된 환경에서 여러 대의 가상 머신이 하이퍼바이저를 통해 처리하던 것을 PCI 디바이스가 처리하도록 만들어 하이퍼바이저에게 발생할 수 있는 병목을 제거하는 기법이다.
스냅샷, 백업, 클론
스냅샷이란 특정 시점에 볼륨에 기록된 블록 단위의 데이터를 보존하는 것으로 저장속도가 상당히 빠른것이 특징이다. 백업은 볼륨에 저장된 데이터를 내구성이 높은 오브젝트 스토리지에 보존하는 것이고 클론은 볼륨을 직접 복재하는 것이다.
Amazon EBS에서는 스냅샷을 만들기 위해 'CreateSnapshot' API를 실행하는데 내부적으로는 Amazon S3에 저장되어 사실상 백업을 하는 것과 같은 효과가 난다. 참고로 Amazon EBS의 스냅샷은 블록 수준에서 만들어져서 같은 볼륨에 대해 두번이상 스냅샷을 만들면 앞에서 만든 블록에 대한 변경경 부분만 S3에 보내진다. 변경된 내용이 적을수록 백업 처리는 빨라지고 최종적으로 S3에 저장되는 형태는 처음 저장된 내용에서 바뀐 부분까지 병합하여 만들어진다.
블록 스토리지의 내부 구성
볼륨을 생성할때 실제로 처리되는 내용은 서버 스토리지 생성 과정과 비슷하다. API를 통해 요청이 들어오면 우선 메시지 큐에 요청 메시지를 넣은 후, 스케줄러가 요청 메시지를 꺼내 어떤 스토리지에 볼륨을 생성할지 판단한 다음 다시 메시지큐에 요청 메시지를 넣는다. 스토리지를 제어하는 에이전트가 메시지큐에서 요청 메시지를 꺼낸 다음 실제 볼륨 생성 작업을 하게 된다.
가상 서버와 볼륨을 연결하는 API는 조금 다른 방식으로 동작한다. 이 둘을 연결하려면 가상 서버와 스토리지 각각의 API를 연계해야 하기 때문이다. 여기서는 서로 다른 리소스를 연계하는 경우를 예를 들어 설명하겠다.
가상 서버와 블록 스토리지 연결

가상 서버와 볼륨을 연결하는 API가 호출할때 오픈스택 내부에서 벌어지는 작업을 도식화 한것이다. 사용자는 가상 서버와 볼륨을 연결하기 위해 가상 서버를 제어하는 API인 'https://{compute}/'를 호출한다. API를 통해 연결 요청이 접수되면 일단 메시지 큐에 요청 메시지를 넣게 되고, 이후 스케줄러가 하이퍼바이저를 선택하고 그 하이퍼바이저가 연결 처리를 하게 된다.
각 하이퍼바이저 안에는 오픈스택 에이전트가 실행되고 있으며 이 에이전트 프로세스가 큐에 등록된 연결 요청 메시지를 꺼내간다. 이때, 하나의 하이퍼바이저에서 끝낼 수 있는 작업이라면 에이전트가 그 하이퍼바이저에서 작업을 처리하게 된다. 하지만 하이퍼바이저 외에도 스토리지와 연결해야하는 경우라면 블록 스토리지 리소스를 제어하는 엔드포인트를 통해 API를 호출하여 서버와 스토리지의 연결에 필요한 일종의 협상과정을 시작하게 된다.
'(2)블록 스토리지와 연결 준비' 부분이 스토리지 연결 요청을 받은 에이전트가 연결 작업을 위한 협상을 하는 부분으로, 스토리지를 제어하기 위해 'https://{storage}/'로 API를 실행하고 있는 것을 알 수 있다. 요청을 받은 엔드포인트는 지정된 볼륨을 연결할 수 있도록 준비 작업을 하는데 가상 서버와 볼륨, 각각의 준비가 완료되면 이 둘은 연결한다. 이와 같이 오픈스택의 API는 사용자만 사용하는 것이 아니라 리소스와 리소스 간의 연계에서 발생하는 자동화 협상과정에서도 나타난다.
클라우드 환경에서 API를 사용하는 것이 익숙한 엔지니어들은 API 형태로는 공통으로 사용하기 어렵다는 이유로 미처 써보지 못하고 숨겨지는 기능이 있을수 있다는 것을 이해해야 한다. 그리고 특정 용도에서는 클라우드를 사용하는 것보다 물리적인 환경에서 제품 고유의 기능을 활용하는 것이 더 유리할 수 있다는 것도 알고 있어야 한다.
어떤 경우에서도 절대적인 해결책은 없다. 엔지니어라면 폭넓은 지식과 기술을 적재적소에 잘 활용할 수 있어야 한다. 그리고 그러기 위해서는 기회가 되는대로 클라우드 이면의 숨은 기능들을 찾아보며 학습할것을 권장한다.

클라우드 리소스 컴포넌트간 내부 연계 동작이 궁금할때는. 표면적으로는 직접적인 관계가 없는 듯한 리소스들의 관계를 규명해야 할때에는 이와 같이 속성으로 연결되는 정보가 있는지 찾아보는것도 좋은 방법이다.
서버 리소스에 NSF를 구성하면 공유 디스크와 같은 역할을 할수는 있지만 이 서버가 단일 장애점(SPOF:Single Point of Failure)이 되 거나 대규모 시스템에서는 병목으로 작용할 수 있다. 이와 같이 여러 서버에서 공유 디스크를 사용하고 싶다는 요구와 NFS만으로는 장애 대응이 어렵다는 제약에 대해 해결방법으로 등장한 것이 바로 NFS 서비스이다.
오픈스택에서 NFS 서비스에 해당하는 것이 Manila인데, Manila는 컴퓨팅 서비스인 Nova에서 NFS 등의 프로토콜로 마운트하는 방식으로 사용되며 접속 인터페이스와 관리형 공유 스토리지를 제공하는 역할을 한다.
클라우드 네트워크 리소스 컴포넌트
클라우드 환경이라고 하더라도 네트워크의 기본은 TCP/IP이다. 네트워크의 기능은 크게 같은 네트워크에 속한 장비끼리 연결되는 L2 네트워크 기능과 서로드 다른 L2 네트워크끼리 연결되는 L3 네트워크 기능으로 구분된다.
클라우드 환경의 네트워크는 기존의 물리적인 네트워크에 비해 몇몇 편리한 기능이 더 많다. 가령 L3 네트워크는 보통 L2 네트워크끼리 연결할때 사용하는데 클라우드의 내외부를 연결하는 기능을 하기도 한다. 또한 클라우드 환경의 네트워크 리소스에는 시큐리티 그룹이라는 방화벽 기능/접근제어/부하 분산/VPN 기능과 같은 다양한 기능들도 적용할 수 있다. 이러한 네트워크 리소스 중에서도 L2와 L3 네트워크는 특히 중요하다.
네트워크 리소스 오버뷰
서버 리소스나 스토리지 리소스는 오픈스택과 AWS 사이에 큰 차이가 없었지만 네트워크 부분에서는 모델링 방식에 일부 차이가 있다. 이러한 차이는 기존 물리적 환경의 네트워크 장비 구성 방식이나 사람이 하던 작업 방식을 프로그램 형태로 바꿔나가는 과정에서 생기는 차이로, 추상화된 기능을 매핑하는 단위와 대상이 다르기때문에 발생하는 차이다. 다만, 모델의 차이는 있지만 기본적인 개념과 접근 방법은 크게 다르지 않다.
기능 매핑
네트워크의 기본 기능들은 L2 네트워크상에서 만들어지는 서브넷의 기능과 그 서브넷들을 서로 연결하기 위한 라우팅 기능, 그리고 서버를 네트워크에 연결하는 논리 포트 기능이다.

오픈스택 Neutron
neutron은 비교적 물리적 환경과 유사한 형태로 모델링이 되어 있는데 테넌트 안에 가상 스위치(가상 네트워크), 가상 라우터, 논리 포트로 구성되는 형태이다.
AWS VPC
AWS에서는 가상 네트워크 전체에 해당하는 VPC라는 리소스를 먼저 만든 후, 그 안에 기능적인 요소로 서브넷, 라우팅 테이블, ENI(Elastic Network Interface)로 구성되는 형태이다. 오픈스택과 비교해보면 오픈스택은 실제 물리적인 네트워크 장비를 흉내내어 모델로 만든 반면, AWS는 논리적인 네트워크의 기능을 모델로 표현하고 있다는 것을 알 수 있다.
오픈스택과 AWS의 네트워크 리소스 비교
오픈스택 Neutron에서는 테넌트에 스위치, 라우터와 같은 리소스를 직접 생성하는 반면, AWS에서는 VPC(Virtual Private Cloud)라는 독립된 사설 네트워크를 생성한 후, 그 안에 서브넷이나 라우터와 같은 리소스를 만들게 된다. 이때 VPC는 테넌트 안에 여러개 만드는 것이 가능하다.
한편, 클라우드 환경의 네트워크에서는 이러한 리소스들을 테넌트 사용자가 자유롭게 만들고 삭제할 수 있다. 이전의 물리적인 인프라 환겨이었다면 네트워크 장비에 직접 손을 댈 수 있는 권한을 가진 담당자에게 요청을 해야 했던 반면, 클라우드 환경에서는 클라우드 사용자가 직접 작업할 수 있는 권한이 있다.
스위치
가상 스위치는 물리적인 네트워크 스위치를 흉내낸것으로 L2 네트워크 기능을 수행한다. 같은 가상 스위치에 연결된 가상 서버들은 별도의 라우팅 설정 없이도 서로 통신할 수 있다.
가상 스위치에는 L3 네트워크에서 사용하는 IP 주소 범위(CIDR이라고도 하며 172.16.1.0/24로 표현)를 '서브넷'이라는 이름으로 할당받는다. IP 주소 범위는 사용자가 자유롭게 정의할 수 있다. 클라우드 환경의 네트워크들은 서로 완전히 분리되어 있기 때문에 네트워크끼리 직접 연결되지만 않는다면 같은 IP 주소가 사용되어도 무방하다. 보통은 공인 IP와 중복되지 않게 하기 위해 사설 IP 주소의 범위에서 할당하는 것이 일반적이다.
오픈스택 Neutron
오픈스택 Neutron에서는 가상 스위치를 '네트워크'라고 하고, 서비넷은 그대로 '서브넷'이라고 부른다. 서브넷 IP 주소 범위는 사용자가 임의로 정할 수 있다. 하나의 네트워크에 여러개의 서브넷을 부여할 수도 있는데, Neutron의 네트워크 모델이 물리적인 네트워크를 흉내내고 있다는 것을 알 수 있다.
AWS VPC(Virtual Private Cloud)
AWS VPC에서는 가상 스위치에 대응하는 리소스는 없고 서브넷에 그 가상 스위치의 개념과 기능이 함께 녹아있다. 이런 형태가 가능한 이유는 대부분의 경우에서 가상 스위치와 서브넷은 1:1 관계이고 TCP/IP를 사용한다는 것을 전제로 하면 서브넷만 정의하더라도 통신하는 데는 충분하기 때문이다.
IP 주소 범위는 사용자가 자유롭게 정의할 수 있는데 보통은 두 단계로 나누어서 정의한다. VPC를 생성할때 그 VPC에서 사용할 IP 주소 범위를 우선 정하고, 이후 서브넷을 생성할때 앞서 정의한 IP 주소 범위 안에서 서브넷에 사용할 범위를 선택하는 방식으로 총 두번에 걸쳐 정의한다. VPC 안에서는 여러개의 서브넷이 만들수 있으나 VPC가 이미 확보한 IP 주소 범위를 나중에 변경하지는 못하기 때문에 향후 사용할 IP 주소 범위까지 미리 예측하여 IP 주소의 범위를 여유있게 정할 필요가 있다.
서브넷
서브넷에 연결된 서버는 기동시 DHCP를 통해 IP 주소를 할당받고 그 IP 주소로 통신하게 된다. 여기서 DHCP로 IP 주소를 받는다고 해서 매번 기동할때마다 다른 IP 주소가 할당되는 것은 아니라는 것을 주의해야 한다. 클라우드 환경에서는 이미 IP 주소가 할당되어 있는데 단지 그 IP 주소가 DHCP를 통해서 전달될 뿐이다. 그래서 한번 기동한 서버는 몇번을 재기동하더라도 같은 IP 주소가 부여된다.
이러한 가상 네트워크 즉, 서브넷은 '할당된 IP 주소에만 통신을 허용한다'라는 특징이 있어서 사용자가 서버 안에서 임의로 IP 주소의 설정을 바꾼다고 하더라도 변경된 IP 주소로는 통신하지 못한다.
클라우드 환경에서는 IP 주소를 자동할당한다거나 통신 범위를 격리시키는 기능이 있기에 과거의 물리적인 인프라 환경에서는 관리자가 엄격하게 관리되던 네트워크 작업들을 일반 사용자들도 손쉽게 제어할 수 있다.
IP 주소의 범위
오픈스택이나 AWS 상관없이 서브넷을 생성할때 지정하는 IP 주소의 범위를 'CIDR: 사이더'라고 부른다. CIDR는 Classless Inter Domain Routing을 줄인 말로 '클래스가 필요없는 내부 도메인 라우팅'이라는 말로 풀이된다. 그런데 왜 라우팅에 관련된 용어가 IP 주소 범위를 표현하는 단어에 쓰인것일까.
그 이유는 IP 주소 할당과 라우팅 기범의 변화 과정에서 답을 찾을 수 있다. IP 주소는 크게 서브넷을 식별할 수 있는 네트워크 파트와 서브넷 안에서 개별 통신 장비를 식별할 수 있는 호스트 파트로 나뉜다. 이때 네트워크 주소의 비트 길이를 서브넷 마스크로 표현한다.
라우터
라우터는 물리적인 라우터 장비와 마찬가지로 서로 다른 네트워크를 연결하는 기능을 한다. '내부→내부 / 내부→외부 / 외부→내부'와 같은 세가지 유형의 연결 방식이 가능한데 여기서 '내부'는 클라우드 네트워크를 의미한다.
첫번째 유형인 '내부→내부' 방식은 같은 네트워크에 속한 서버끼리 통신하는 것으로, 기본적으로 테넌트 내부나 VPC 내의 네트워크들을 서로 연결하게 된다. 경우에 따라 서로 다른 테넌트의 네트워크와 테넌트의 경계를 넘나들면서 라우팅해야 하는 경우도 있는데 이때는 AWS에서는 VPC Peering이라는 기능을, 오픈스택 Neutron에서는 네트워크 공유 기능을 사용하면 된다.
라우터의 주요 역할 중에는 클라우드 환경의 사설 네트워크와 인터넷과 같은 외부 네트워크를 서로 연결해주는 것이 있는데, 이는 두번째 유형인 '내부→외부' 연결에 해당한다. 즉, 가상 네트워크에 연결된 서버가 인터넷을 통해 외부에 접속되는 경우를 말하는데, 이때 라우터에서는 내부 네트워크에서 사용되는 사설 IP 주소를 공인 IP로 변환하는 IP 마스커레이드를 하게 된다.
세번째 유형인 '외부→내부' 방식은 외부에서 클라우드 내의 서버에 접근하는 방식으로 오픈스택에서는 플로팅 IP, AWS에서는 EIP(Elastic IP)가 사용된다. 이러한 기능은 공인 IP를 어드레스 pool에서 확보한 다음, 서버의 논리 포트에 할당하고 다시 이 공인 IP 주소가 사설 IP 주소로 연결되도록 만든다. 이렇게 하면 클라우드 외부에서 클라우드 내부로 접근할 수 있게 되는데 이러한 기능을 NAT(Network Address Translation)이라고 한다. 참고로 공인 IP의 주소 풀은 리전별로 관리되는데 AWS의 경우 'AWS IP Address Ranges'에서 공인 IP 주소의 범위 정보를 JSON 형식으로 받아볼 수 있다.
오픈스택 Neutron
Beutron의 리소스 모델은 크게 가상 라우터와 서브넷의 연결 관계로 구성된다. 이것은 실제로 물리적인 네트워크 환겨에서 라우터 인터페이스에 네트워크 케이블을 꽂는 것과 유사하게 라우터를 생성한 다음, 이 라우터의 인터페이스에 서브넷을 연결하는 방식이 된다. 그래서 Neutron 내부에서는 서브넷이 할당된 네트워크에 논리포트를 만들고 이 논리 포트를 라우터에 연결한다. 외부와의 연결에서도 같은 방법으로 외부 네트워크에 논리 포트를 만들고 이 논리 포트를 라우터에 연결하면 된다.
연결된 후에는 가상 라우터와 서브넷의 연결 상태에 따라 가상 라우터의 라우팅 테이블이 갱신되고 이 라우팅 테이블 정보에 따라 전송 트래픽이 흘러간다. 이와 같이 오픈스택은 물리적인 네트워크와 형태가 거의 비슷하다.
두개의 서브넷이 라우터를 통해 연결되어 있지만, 경우에 따라서 두 네트워크 사이에서 통신을 차단하고 싶을 수도 있다. 이때는 가상 라우터를 두 개 만들고 외부 네트워크에 연결한 다음 서로 다른 두 서브넷을 앞서 만들어놓은 가상 라우터 각각에 하나씩 연결하면 된다. 이렇게 하면 두 서브넷끼리는 통신하지 못하지만 외부와의 통신은 할 수 있게 된다.
AWS VPC
AWS VPC의 가상 라우터는 오픈스택의 Neutron과는 조금 다른 형태로 모델링되어 있는데 크게 게이트웨이와 라우팅 테이블로 구성된다. AWS에서는 외부로 연결하기 위해 VPC 안에 게이트웨이를 만든다. 그런 후, 서브넷의 '라우팅 테이블'에서 외부로 통신할 때는 이 게이트웨이를 통과하도록 라우팅 정보를 설정해주면 된다.
게이트웨이는 그 역할에 따라 몇가지 분류가 가능한데, 인터넷 통신을 하기 위한 IGW(인터넷 게이트 웨이), VGW(거점과 사설 네트워크 통신을 하기 위한 버추얼 게이트웨이), PCX(리전 안에서 서로 다른 VPC끼리 연결하기 위한 피어링 커넥션), 인터넷에 연결된 매니지드 서비스에 VPC에서 인터넷을 경유하지 않고 연결하기 위한 VPC 엔드포인트 등으로 나눌 수 있다.
수신지가 Any인 '0.0.0.0→IGW'와 같은 라우팅 규칙을 공용 세그먼트인 '172.168.1.0/24'에 적용하면 공용 세그먼트만 인터넷 접속 가능하게 만들 수 있고 온프레미스 거점의 CIDR에서 시작하는 '10.0.0.0/8→VGW'와 같은 라우팅 규칙을 사설 세그먼트인 '172.168.2.0/24'에 적용하면 사설 세그먼트만 거점에 접속 가능하게 만들 수 있다.

AWS에서는 개념적으로 라우터가 VPC에 속하는 형태지만 실제로 라우터가 리소스 형태로 관리되지는 않는다. 대신 라우터에 설정하는 '라우팅 테이블'을 리소스 형태로 사용하게 되는데 이 리소스는 VPC 전체와 개별 서브넷에서만 적용할 수 있다. VPC 전체에 적용한 것을 메인 라우팅 테이블이라고 하고 특정 서브넷에만 적용하는 것을 서브 라우팅 테이블이라고 한다.
포트
논리 포트는 가상 네트워크상에 만들어지는 스위치의 포트같은 개념이다. 오픈스택 Neutron과 AWS, 두 서비스 모두에 있는 공통적인 개념으로 Neutron에서는 가상적인 스위치의 접점이라는 의미가 강하고 '논리 포트'라고 한다. AWS에서는 서버에서 네트워크에 연결하기 위한 인터페이스 접점이라는 의미가 강하고 'ENI: Elastic Network Interface'라고 부른다.
이렇게 만들어진 논리 포트에 서버나 가상 라우터를 연결해서 사용하면 되는데 물리적인 네트워크 환경에서는 스위치가 단순히 네트워크 케이블을 연결하여 전기적인 신호를 주고받는 일종의 커넥터 역할을 했다면 논리 포트는 여기에 몇가지 유용한 기능이 더 추가되어 있다.

논리 포트는 생성될때 자신이 소속된 가상 서브넷으로부터 IP 주소를 할당받게 된다. 그리고 이때 할당된 IP 주소 이외의 통신은 모두 차단시킨다. 논리 포트에는 IP 주소를 여러개 할당할 수 있기 때문에 가상 서버의 NIC 하나에 여러 개의 IP 주소를 부여하는 것이 가능하다. 또한 하나의 가상 서버에 여러개의 논리 포트를 할당할 수도 있다.
이러한 논리 포트는 서버를 가상 네트워크에 연결할때만 쓰는 것이 아니라 가상 네트워크와 가상 라우터를 연결할때도 사용된다. 이것은 물리적 환경의 네트워크에서 물리 스위치의 포트에 물리 라우터를 연결하는 것과 같은 형태가 된다. 이렇게 논리 포트와 가상 라우터가 연결되고 나면 논리 포트에 할당된 IP 주소는 가상 서브넷의 게이트웨이 역할을 한다. 결국 논리 포트를 통해 서브넷에 연결되어 있는 가상 서버는 이 게이트웨이를 통해서 클라우드 안팎에 있는 다른 네트워크와 통신할 수 있게 된다.
비슷한 방식으로 외부에서 내부로 접근할때 사용되는 플로팅 IP(AWS VPC에서는 Elastic IP)도 이 논리포트에 할당된다. 플로팅 IP를 통해 들어오는 요청은 가상 라우터에 의해 NAT 처리된 후, 논리 포트의 IP 주소로 전달된다.
논리 포트는 IP 주소 외에도 MAC 주소도 가지는데 IP 주소가 논리적인 L3 네트워크의 정보인 반면, MAC 주소는 물리적인 L2 네트워크의 정보다. 이 MAC 주소는 나중에 논리 포트와 가상 서버가 연결될 때 가상 서버 NIC의 MAC 주소로 사용된다.
네트워크 액세스 컨트롤 리스트(NACL)
AWS에서는 서브넷에 대해 필터링을 하는 네트워크 액세스 컨트롤 리스트(NACL: Network Access Control List)라는 기능이 있다. 네트워크를 설계할때, 서브넷에 역할을 부여하게 되는데 명시적으로 패킷 필터링을 하거나 권한을 분리하는 것이 가능하다.
기본적인 필터링 방법은 크게 다르지 않지만 차이가 있다면, NACL이 기본 설정이 암묵적으로 접근을 허가한다. 반면 시큐리티 그룹은 기본 설정이 암묵적으로 접근을 금지하도록 만들어져 있다. 그래서 NACL은 접근 제어를 할때 명시적으로 금지하는 방식으로 설정하고 시큐리티 그룹은 명시적으로 허용하는 방식으로 설정한다.
접근 제어를 언급할때 state, 혹은 상태의 유지 여부에 따라 동작 방식이 달라질 수 있는데, 여기서 상태라는 것은 통신에 대한 허용 여부 정보에 대한 상태라고 생각하면 된다.
NACL의 규칙은 상태가 없는 stateless이다. 그리고 암묵적인 접근 허가 방식이다. 통신이 들어오는 inbound도 기본적으로 허용이고 나가는 outbound도 기본적으로 허용이다. 나가는 통신을 막고 싶다면 아웃바운드만 명시적으로 금지하면 된다.
시큐리티 그룹은 상태를 가지는 stateful이며, 암묵적인 접근 금지 방식이다. 통신이 들어오는 인바운드도 기본적으로 금지이고 나가는 아웃바운드도 기본적으로 금지이다. 들어오는 인바운드 통신을 허용해주면 나가는 아웃바운드가 기본적으로는 금지였지만, 인바운드 통신을 명시적으로 허용해주었고 그상태도 유지되기 때문에 아웃바운드로 나가는 통신이 허용되는 효과가 나온다.

참고로 오픈스택 Neutron에도 이와 같은 기능이 FWaas(Firewall-as-a-Service)라는 이름으로 개발 진행되었다.
과거의 물리적인 인프라 환경에서 같은 작업을 한다면 우선 라우터의 라우팅 설정은 어떻게 할지, 서버에 할당할 주소는 어떤 것을 사용할지 등과 같은 다양한 검토가 필요하다. 그리고 각종 네트워크 장비를 설정하려면 각 장비별 설정 가이드를 숙지해야 하는 등, 하나의 네트워크 세그먼트를 만드는데도 상당한 많은 노력이 필요할 것이다. 하지만 클라우드 환경의 네트워크는 과거에 수행했던 복잡한 작업들을 모두 은폐했고, 사람이 각종 의사결정을 해야 했던 부분 역시 자동으로 대신해 주어 과거에 비해 네트워크를 상당히 효율적으로 구축할 수 있다.
Neutron은 사용하는 드라이버에 따라서 Cisco/Juniper와 같은 다양하 네트워크 기기들을 제어할 수 있다. 네트워크 분리를 구현하기 위해 리눅스에서 오픈소스로 제공되는 OVS(Open vSwitch)를 내부적으로 활용하고 있다.
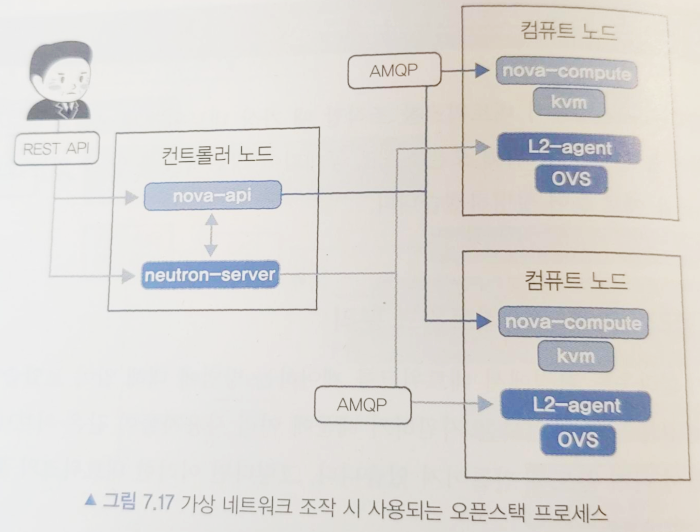
오픈스택에서 사용자가 실행한 API는 nova-api나 neutron-server의 프로세스가 접수한다. 이때 이들의 프로세스가 동작하는 호스트를 '컨트롤러 노드'라고 한다. 그리고 실제로 KVM(Kernel-based Virtual Machine)에 의해서 가상 서버를 기동하고 OVS로 가상 네트워크를 구성하는 호스트를 '컴퓨트 노드'라고 부른다. 이 컴퓨트 노드에는 KVM을 제어하는 nova-compute 프로세스와 OVS를 제어하는 L2-agent가 동작한다. 한편, 사용자는 컨트롤러 노드에 가상 서버나 가상 네트워크에 대한 제어 요청을 보내고 컨트롤러 노드에서는 접수한 요청에 대해 nova-api와 neutron-server, 혹은 또 다른 오픈스택 프로세스들과 연계하면서 컴퓨트 노드를 제어하게 된다.

OVS 브릿지 br-int는 br-tun과 연결되어 있다. br-tun은 컴퓨트 노드 사이에서 패킷을 전송하는 역할을 한다. 패킷을 전송할 때는 VXLAN이 사용되는데 VXLAN ID가 설저된 패킷을 br-tun에 보내면 그 뒤에 연결된 VXLAN 인터페이스를 통해 각 컴퓨트 노드까지 전달된다. 여기서 VXLAN은 이더넷 프레임을 캡슐화해서 L3 네트워크상에 논리적인 L2 네트워크를 구성하는 터널링 프로토콜이다.
가상 서버에서 전송되는 패킷은 연결된 가상 인터페이스를 보고 자신이 어떤 네트워크에 속해있는지 알 수 있다. 그래서 이 패킷이 이 가상 네트워크에서 나왔다는 것을 알 수 있도록 VLAN ID를 패킷에 할당한다. 같은 컴퓨트 노드 안에서는 서로 다른 가상 네트워크들의 서로 다른 VLAN ID를 가지기 때문에 결과적으로 네트워크를 격리하는 효과가 있다. 그래서 같은 호스트 안에서 같은 IP 주소를 사용하더라도 패킷의 VLAN ID로 구분이 가능하여 충돌이 발생하지 않는다.
VXLAN을 사용해서 가상 네트워크를 식별하는데 다른 네트워크 가상화 기술에서도 이런 원리를 이용하여 고유한 ID를 부여하고 가상 네트워크를 구분하는 기법이 사용된다. 그래서 어떤 네트워크 가상화기술을 사용할지 결정할 때에는 식별해야 하는 가상 네트워크의 개수와 성능, 운영 효율 등의 여러 특성들을 고려하여 선택해야 한다.
클라우드 환경에서의 시스템 구축에 있어서 네트워크 시큐리티는 상당히 중요한 부분이다. 그래서 대규모 시스템을 구축할 때는 네트워크 설계와 필터링 정책을 반드시 검토해야 한다. 특히 시큐리티 그룹과 NACL은 설정에 대한 자유도가 높고 N:N 관계를 만들수 있기 때문에 보다 이해하기 쉬운 형태로 설계하기 위해서는 어떤 규칙들을 만들지, 규칙이 변경될때 어떻게 반영을 할지 등에 대해 충분히 고민해야 한다.
스토리지는 크게 세 종류로 구분할 수 있다.
1. 블록 스토리지
스토리지 관점에서는 블록 단위로 데이터를 인식하게 되고, OS 관점에서는 블록 스토리지 안의 파일들을 파일 시스템상의 다른 파일들과 동일하게 인식하고 처리할 수 있다. 서버 관점에서는 스토리지를 디바이스로 인식하는데 주로 로컬 디스크나 데이터베이스를 사용하면서 온라인 시스템의 정보 처리 용도로 많이 활용된다.
2. 네트워크 스토리지
서버가 이런 유형의 스토리지를 사용할때는 TCP/IP로 네트워크에 연결해야 한다는 특징이 있는데 이때 사용되는 대표적인 프로토콜이 NFS이다. 클라우드에서도 이와 유사항 NFS 서비스를 제공한다. 한편, 이러한 네트워크 스토리지는 NFS 서비스를 마운트해서 사용하기 때문에 OS의 파일 시스템 관점에서는 다른 파일들과 다를바 없이 똑같이 파일로 인식하게 된다.
3. 오브젝트 스토리지
이런 유형의 스토리지는 파일 단위로 데이터를 관리하고 HTTP/HTTPS 프로토콜로 데이터에 접근한다는 특징이 있다. 파일 시스템에 해당하는 기능들은 오브젝트 스토리지 측에서 제공하는데 서버의 OS 관점에서 이 스토리지를 마운트해서 사용하는 경우는 거의 없고 대부분 개별적인 파일 단위로 사용한다. 이러한 스토리지는 만들어진지 얼마 되지 않은 비교적 새로운 스토리지 유형이다. 오브젝트 스토리지는 클라우드 서비스나 어플라이언스, 그리고 소프트웨어 형태로 제공되는데 최근에는 유독 클라우드 서비스에서 활용되는 빈도가 높아지고 있다.
오브젝트 스토리지 리소스
서버와 블록 스토리지를 사용해서 웹사이트를 구성한다면 OS에는 Apache, Nginx, IIS와 같은 웹서버를 설치하고 공개할 파일을 배치하는 등의 일련의 작업들이 필요하다. 오브젝트 스토리지를 사용하면 이런 작업은 필요가 없기 때문에 비교적 손쉽게 웹사이트를 만들고 서비스할 수 있다.
오브젝트 스토리지가 HTTP서버, 파일 시스템, 마운트 기능을 모두 포함하고 있다.
가상 서버와 블록스토리지를 사용하여 웹 사이트를 구축한 경우와, 오브젝트 스토리지만 사용하여 웹사이트를 구축한 경우를 살펴본다. 오브젝트 스토리지에는 HTTP 서버, 파일 시스템, 네트워크 디바이스 접속까지 필요한 내용은 모두 포함하고 있기 때문에 복잡한 설정 작업이 많이 줄어든다. 가상 서버와 블록 스토리지를 조합하는 방식보다 상대적으로 쉽고 간단하게 웹서버를 구성할 수 있다는 것을 알수 있다.
블록 스토리지의 파일은 클라우드 환경에서는 리소스로 인식되지 않고, 서버리소스의 파일 시스템에서 인식한다. 블록 스토리지 자체는 리소스로 인식되어 API로 제어할 수 있지만, 파일은 API가 아닌 OS 명령으로 제어해야 한다. 반면, 오브젝트 스토리지에서는 파일 자체를 클라우드에서 제어할 수 있기 때문에 API를 사용하여 제어가 가능하다. 바로 이러한 특징이 블록 스토리지와 오브젝트 스토리지의 가장 큰 차이점이고, RESTful API의 사상을 그대로 적용할 수 있다는 점에서 클라우드 네이티브한 애플리케이션을 만드는 기반 기술이 된다.
오브젝트 스토리지에는 기본적으로 파일을 여러 곳에 replication하는 기능이 있어 백업을 따로 할 필요가 없다. 반면 블록 스토리지를 사용할때는 파일을 원격지에 분산 저장하여 동기화를 시킨다거나 스냅샷을 활용한 백업 등을 고려해야 한다. 내구성 측면에서는 오브젝트 스토리지가 블록 스토리지보다 상대적으로 우수하다.
오브젝트 스토리지를 사용할때는 서비스에 필요한 용량 산정에 크게 고민하지 않아도 된다. 블록 스토리지를 사용한다면 미리 필요한 저장 용량을 예측한 다음 블록 디바이스를 OS에 마운트할때 용량을 정해줘야 하고, 실제 서비스를 운영중이라면 미리 산정한 용량을 초과하지 않도록 감시해야 한다. 이에 반해 오브젝트 스토리지를 사용하는 경우에는 총 용량에 대해 신경쓸 필요가 없다.
클라우드에서는 이러한 오브젝트 스토리지의 특징을 살려서 정적인 웹사이트나 용량이 큰 동영상 파일을 제공할때 활용하거나, 빅데이터와 같이 데이터 양이 폭발적으로 늘어나서 분석이 쉽지 않은 로그 파일을 저장하는데 활용한다. 또한 최근에 오브젝트 스토리지를 데이터 스토어로 사용하는 빅데이터 분석이나 백업 DR을 위한 클라우드 서비스나 서드 파티 소프트웨어가 만들어지고 있다. 데이터를 오브젝트 스토리지에 넣어두기만 하면 이러한 서비스나 소프트웨어에서 간단히 이용할 수 있기 때문에 주요 업무의 데이터 스토어로 오브젝트 스토리지가 활용되는 사례가 늘고 있다.
반대로 안정적으로 높은 I/O 성능을 내야하고 파일의 정합성을 보장하기 위한 lock까지 고려해야 한다면 블록 스토리지를 사용하는 것이 유리하다.
오브젝트 스토리지를 구성하는 리소스
오브젝트 스토리지는 기본적으로 파일을 관리하는 목적으로 만들어졌고 '어카운트', '버킷(컨테이너)', '오브젝트'의 세가지 리소스로 구성된다.
어카운트는 테넌트에 해당한다. AWS에서는 기본적으로 어카운트가 적용되어 있어서 평소에 특별히 그런 개념이 있는지 의식하지 못한다. 그래서 나중에 여러 개의 어카운트끼리 버킷을 공유하는 교차 계정 권한 혹은 크로스 어카운트 기능을 사용할때가 되어서야 인식하게되기도 한다.
버킷/컨테이너는 특정 버킷에 접근할 수 있으려면 버킷의 이름이 고유해야 하는데, 오픈스택에서는 어카운트의 범위 안에서만 컨테이너(버킷) 이름이 고유하면 된다. 반면, Amazon S3에서는 버킷 이름이 인터넷 상에 FQDN으로 공개되기 때문에 어카운트의 범위 밖에서도 고유해야할 필요가 있다.
오브젝트는 버킷 안에 저장되는 파일을 말한다. 버킷 안에 버킷을 중첩해서 넣는 것은 불가능하지만, 디렉터리나 폴더 경로처럼 prefix를 접두어로 하여 분류 체계를 만드는 것은 가능하다. 이때 프리픽스와 파일명을 포함한 것을 key라고 부른다. 이러한 키는 오픈스택에서는 'Account/Container/Object'와 같은 형태를 사용하고 Amazon S3에서는 어카운트가 생략된 'Bucket/Object'와 같은 형태를 사용한다.
최상위에 어카운트가 있고 그 아래에 버킷이 있다. 어카운트 안에는 여러개의 버킷을 만들수가 있기 때문에 '어카운트:버킷 = 1:N'이라는 관계가 만들어진다. 버킷 아래에 오브젝트가 들어가고 버킷 안에는 여러개의 오브젝트를 만들수 있으므로 '버킷:오브젝트 = 1:N'의 관계가 된다. 일반적인 파일 시스템에서도 마찬가지겠지만 같은 오브젝트라고 하더라도 저장되는 곳이 다르면 서로 다른 리소스로 취급된다.
멀티파트 업로드하기
오브젝트 스토리지는 조작할 수 있는 파일 크기에 제약이 있다. 또한 파일 크기가 커질수록 전송할때 부하가 더 커져서 스루풋을 향상시킬 목적으로 파일을 분할한 후, 병렬로 처리하고 싶어질 수 있다.

오브젝트 스토리지는 이러한 요구 사항을 지원하기 위해 멀티파트 업로드(multipart upload)라는 기능을 제공한다. '오브젝트를 분할해서 파트를 생성 → 생성된 파트를 업로드 → 파트를 결합해서 원래의 오브젝트 생성' 크게 세 단계로 동작한다.
멱등성과의 관계
멱등성은 '몇번을 실행해도 같은 결과가 나온다'라는 특성이다. SOA나 REST의 설계 지침에는 이러한 특성이 기본적으로 녹아있다. 오픈스택 Switf나 Amazon S3는 GET이나 HEAD는 물론, PUT과 DELETE까지도 멱등성이 보장되도록 만들어져 있다. 오브젝트를 생성할 때와 변경할때의 두 경우에 모두 PUT이 사용된다. 이는 똑같은 오브젝트를 몇번이든 PUT 하더라도 그 오브젝트가 저장되어 있다는 사실은 변함이 없고 똑같은 오브젝트를 몇번이든 DELETE 하더라도 그 오브젝트가 삭제 되었다는 사실에는 변함이 없다는 것을 의미한다. 이런 동작 방식은 기본적으로 이전 버전을 가잔 마지막 버전으로 덮어쓰면 된다는 단순한 논리로 만들어졌기 때문에 비교적 단순한 형태로 최종 정합성을 구현한 것이라 말할 수 있다.
오브젝트 스토리지의 내부 구성
액세스 티어의 아키텍처 (프론트: HTTP 요청을 접수하는 액세스 tier)
오브젝트 스토리지는 HTTP 프로토콜을 통해 파일을 주고 받는다. 그래서 오픈스택은 액세스 티어에 HTTP 프록시가 구성되어 있고 대량의 HTTP 요청에도 견딜수 있도록 로드밸런서를 두어 부하를 분산하고 있다.
실제로는 HTTP보다 HTTPS가 더 많이 사용되기 때문에 SSL 처리도 여기서 하게된다. 요청한 오브젝트가 없거나 요청이 너무 많이 들어와서 허용된 상한 값을 초과하는 경우, 혹은 인증이 실패하는 경우와 같이 오류가 발생할 때는 HTTP 에러를 클라이언트에게 전달해줄 필요가 있는데 이기능도 액세스 티어에서 해준다.
백엔드인 스토리지 노드에 대한 접근 제어 설정을 Ring이라고 하고, Ring은 스토리지에 저장된 엔티티의 이름과 실제 물리적인 저장 위치를 연결시킨다. Ring은 Swift의 핵심 컴포넌트로 스토리지 노드에 대한 replica 개수, 파티션, 디스크 정보가 설정된다.
Ring은 어카운트, 컨테이너(버킷), 오브젝트 각각에 대해 정적인 해시 테이블을 가진다. 이 해시 테이블은 파티션 정보와 스토리지 노드의 존을 연결해주는 역할을 하는데 이대 파티션 정보에 MD5 해시 알고리즘을 적용해서 스토리지 노드의 존에 분산 배치하기 위한 매핑 정보를 만든다.
스토리지 노드의 아키텍처(백엔드: 오브젝트를 데이터로 저장하는 스토리지 노드)
오브젝트를 저장하는 스토리지 노드군을 존이라고 부른다. 내구성을 높이기 위해 존들은 서로 물리적으로 분리되어 있고, 오브젝트가 저장될때에는 Ring에 설정되 replica 정보에 따라 분산 배치할 존이 정해진다. 파일의 리플리케이션은 어카운트/컨테이너(버킷)/오브젝트 각각의 파일에 대해 별도로 처리된다.
리플리케이션 할때는 확인/복사의 두 단계로 처리하는데 내부적으로는 replicators라는 파일 동기 프로세스가 이런 작업을 수행한다. replicator는 파일의 복사본이 Ring에 설정한 존에 제대로 잘들어 있는지 확인하기 위해 정기적으로 각 파티션을 살펴보는데 이대 해시와 타임스탬프 정보를 서로 비교한다. 이렇게 하는 이유는 용량이 큰 오브젝트 자체를 서로 비교하려면 존과 존 사이에서 TCP 통신을 하면서 불필요한 오버헤드가 발생할 수 있기 때문이다. 그래서 파일 자체를 비교하는 대신 메타 데이터로 관리되는 해시와 타임 스탬프 정보를 비교하는 것이다. 이 방법을 사용하면 오브젝트의 크기나 종류에 상관없이 불필요한 통신 오버헤드를 줄이면서 파일을 분산하여 관리할 수 있다.
Ring 설정에서 파티션은 분산하여 저장할 곳의 크기를 결정하기도 한다. 파티션의 개수가 많으면 많을수록 해시도 늘어나므로 실제로 저장될 존이 어느 한쪽으로 몰리는 편중 현상이 줄어든다. 참고로 Ring 설정에 들어가는 디스크의 정보로는 존/IP 주소/디바이스명(마운트 포인트) 등이 있다.
읽기, 쓰기의 동작 방식
오브젝트를 읽고 쓰는 방식, API로 표현하면 GET, PUT 하는 방식에 대해 알아보겠다. 오브젝트는 여러개의 존에 분산되어 있다. Read를 할때는 GET 요청이 실행되는데 분산된 존 중 한 곳에서 오브젝트를 읽어온다. 이것은 API 요청이 들어오면 부하 분산을 해서 어느 한 존이 처리하도록 한다는 의미로, 같은 요청이 여러번 들어오면 다른 존의 파일을 가져가도록 분산된다는 말이기도 하다.
Write를 할때도 기본적인 동작은 비슷하다. POST나 PUT 요청이 실행되면 부하를 분산하고 여러 존 중에서 결정된 한 존에 오브젝트를 생성하거나 변경한다. 생성이나 변경이 완료되면, 이후 Ring에 설정된 다른 존에 이 파일을 리플리케이션 한다.
이러한 동작 방식을 자세히 살펴보면 Read를 할때는 Ring에 설정된 존에만 접근하며 되고 Write 할때는 Ring에 설정되 레플리카 전체에 접근해야 하기 때문에 HTTP 프록시에 병목만 걸리지 않는다면 Read를 Write보다 더 많이 처리할 수 있다는 것을 알 수 있다. 대부분 Read의 빈도가 Write보다 더 많기 때문에 그러한 상황을 고려한 아키텍처 설계라고 생각하면 된다.
파티션과 타임 스탬프의 관계
오픈스택 Swift에서는 파티션과 존을 매핑할때 해시 알고리즘을 사용한다. 이 해시 값은 내부적으로는 파티션 번호를 사용해서 산출하는데 자세히는 오브젝트의 키이름을 사용한다. 파일이 변경되더라도 키 이름이 바뀌지 않는 경우라면 PUT 요청이 실행되더라도 해시 값이 바뀌지 않는다. 리플리케이터는 해시 값과 타임 스탬프 정보를 보고 처리하기 때문에, 이대는 타임 스탬프 정보만 비교하게 된다. 오픈스택 Swift는 파일명을 만들때 타임스탬프를 활용하기 때문에 이 파일을 rsync로 동기화하면 바뀐 내용을 자동으로 반영할 수 있다.
이러한 동작 방식을 잘 보면 삭제할때는 제대로 동작하지 않을 수 있다는 것을 알수 있다. 그래서 오픈스택 Swift에서는 삭제할때는 .ts(tombstone) 파일을 만들어서 논리적으로 삭제되었다고 인식시킨다. 이 방법은 DELETE를 할 때의 멱등성을 보장하기 위해 꼭 필요한 구현 기법이다.

프리픽스와 분산의 관계
앞서 Read와 Write를 할때 여러 존으로 분산되어 처리되는 것을 확인하였다. 이때 사용되는 MD5 해시 알고리즘을 최적화할 수 있다면 파일을 각 존에 분산할때 좀더 고르게 저장되도록 만들수도 있다.
해시 값을 산출할때는 파티션 정보를 이용하는데 그 정보에는 프리픽스가 포함되므로 결국 프리픽스를 잘 설계하는 것이 파일을 균일하게 분산하는 중요한 요소가 된다.
MD5는 입력으로 주어진 값을 받아 16진수, 128(2^16)비트의 값을 만든다. 파티션 정보는 프리픽스로 시작하기 때문에 프리픽스의 첫 문자를 얼마나 무작위로 잘 만들어내느냐가 분산시키는 정도를 결정한다. 예를 들면 Amazon S3에서는 오브젝트 스토리지의 입출력 퍼포먼스를 향상시키기 위해 프리픽스 첫문자에서 3~4번째 문자까지를 16진수로 1에서 F까지 순차적으로 부여하는 방식이 사용된다.

'IT' 카테고리의 다른 글
| [인프라] 도커 네트워크 (0) | 2019.07.29 |
|---|---|
| [인프라] 아티팩트 저장소(artifact repository) (0) | 2019.07.29 |
| [인프라] 클라우드 CDN 아키텍처 (0) | 2019.07.29 |
| [Linux] 우분투에서 이클립스 설치하기 (0) | 2019.07.27 |
| [Linux] 우분투에서 오라클 설치하기 (0) | 2019.07.27 |



